こんにちは!Pythonに手を出してみたS.K.です。
今回はPythonの定番のアレです。そうスクレイピングです!!
ちなみにスクレイピングとは、ウェブサイトから情報を取得して、その情報を新たな情報に加工・生成することです。Webスクレイピングとも呼ばれたりします。
例としては、ニュースサイトの見出しだけを一覧にしたり、商品のデータを集めて価格表にしたりするといったものですね。
今回は、ある資格試験の過去問からデータを取得してみました。
問題文と選択肢、解答を取得し、ついでに画像も取得できるようにしています。(問題文の中に画像があったり、選択肢が画像だったりするため、それを取得するためのものです)
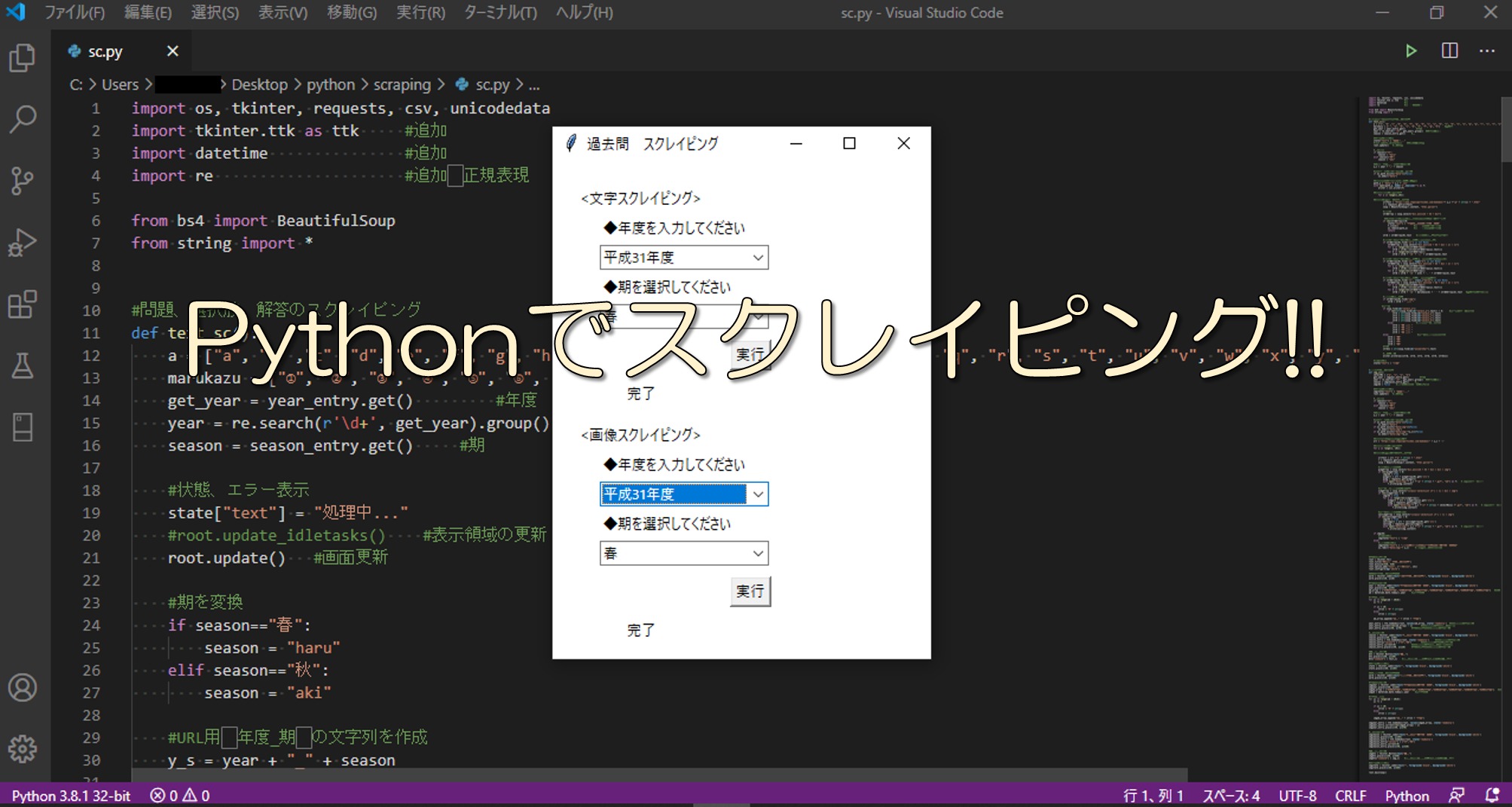
画面はもちろんGUI!!
使用頻度は半年に1度なんですけどね(笑)
なんかいろいろ触っていたら、どんどんこだわりが出てきてしまいました。
GUI画面を使うことで、より使いやすさが向上した感じなっています。
それでは、紹介していきます。
これでスクレイピングをしてみよう!!
何はともあれ、どんなのなの?と思われるせっかちなあなたに、今回作ったプログラムを動かしている動画です。
操作はとっても簡単、欲しい過去問の年度と期を選択して実行ボタンを押すだけです。
文字や数字を入力する必要がなく、選択だけでできるのはGUI画面だからですよね。手前味噌ですがかなり便利です。(もちろんこんなにこだわらなくてもCUI画面で文字や数字を入力したらスクレイピングを行うプログラムをつくることもできますよ。)
文章と画像で項目が分かれているのは、文章だけが欲しい!とか画像だけが欲しい!とかいう人がいるからです!!
はい、嘘です。いや嘘でもないんですが(どっちやねん)
動画見ていただければわかるのですが、スクレイピングって結構時間がかかるんですよ。その中で文章も画像もとなると、かかる時間はさらに倍!!になってしまうため、項目を分けたという理由もあります。
今回、文章はCSVファイルに書き込んでいるので、なおさら時間がかかっているんですけどね。
「文章のどこに画像入るかわかんねーよ。」と思われた方、安心してください、わかるようになっていますよ。
例えば下の画像のように問題文中に画像がある場合はCSVの文章中に「■画像■」と表示するようにしています。また、画像もファイル名を「q77.gif」となるようにしていて、「q=question、77=77問目」とわかるようにしています。
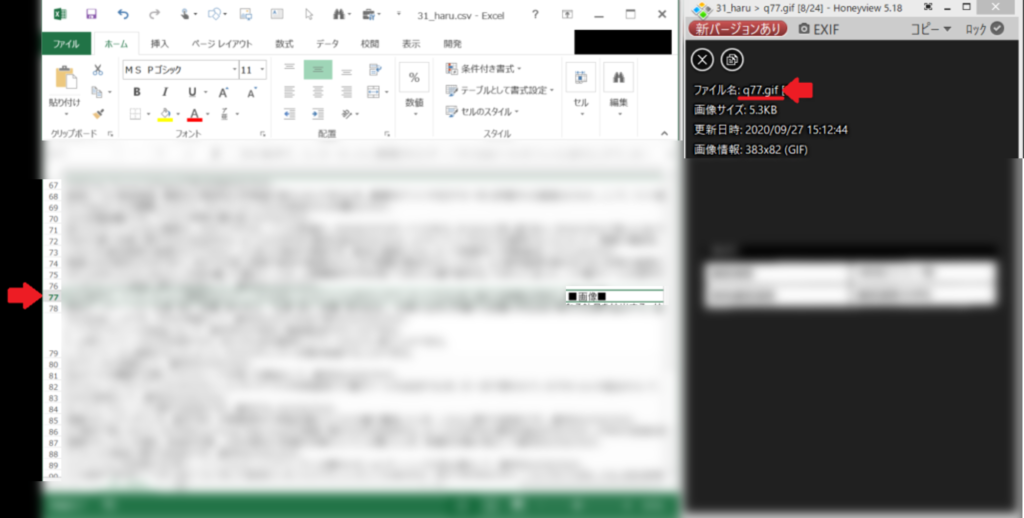
なので、2つを比較すればどこにどの画像を入れればいいかが丸わかりですよね!!
もちろん、スクレイピングを行い取得した文章と画像を一つの表にまとめることもプログラムできますが、今回は「問題をランダムに並び替えて表示したい」とか「ランダムに5問だけ使いたい」のように自由にデータを使えるようにしています。
取得したデータがどのように扱われるかを考えて、使いやすい形にするようにするもの大切なことですね。
利用される環境を考えてプログラムを設計すると成長につながりますよ。
スクレイピングのやり方は?
今回GUIを扱うためにtkinterを使い、スクレイピングはBeatifulSoupを使っています。その他にもいろいろです。
スクレイピング(html全文のデータの取得)をしているのは
|
1 2 3 |
urlText = "https://xxx/xxx" r = requests.get(urlText) soup = BeautifulSoup(r.content, "html.parser") |
たったこれだけなんです。
ですが、別にhtml全文のデータなんて別にいりませんよね?
取得したhtml全文のデータから自分が欲しいデータだけに加工するためにあれこれをする日鬱洋画あります。この加工するためのあれこれというのはhtmlの知識が必須になってきます。
例えば、問題文中に順序のあるリストがあったときは
|
1 2 3 4 5 6 |
if strQArray[0].find('ol', type="a") is not None: strQSArray = soup.select("div.anslink + h3 + div > ol > li") for j in range(len(strQSArray)): strQ = strQ[:-1*(len(strQSArray[j].text))] for k in range(len(strQSArray)): strQ = strQ + '\n' + a[k] + '. ' + strQSArray[k].text |
のように書いています。
これは、olタグにtype=”a”があった場合、
「div.anslink」 の次の 「h3」 の次の 「div」 の中の 「ol」 の中の 「li」を取得しています。
取得するwebページのhtmlがどのようになっているかを確認して、欲しい部分を狙いうちしているイメージですね。
このように取得したデータに狙いを絞るためにも、ある程度のhtmlの知識は必要になってきます。
また、今回初めて使ったのがコンボボックスです。
値を選択するだけになるのですごく便利ですよね。使うことでユーザビリティの向上につながりますよ。
|
1 2 3 4 |
season_entry = ttk.Combobox(root, state='readonly') #コンボボックスを作成 season_entry["values"] = ("春","秋") #コンボボックスに表示する値 season_entry.current(0) #コンボボックスの初期値を設定(春) season_entry.place(x=40, y=120) #ウインドウにコンボボックスを設置 |
コンボボックスに表示する値(values)はコンボボックスを作成した際に入れることもできます。
|
1 |
year_entry = ttk.Combobox(root, values=ad_array, state='readonly') #コンボボックスを作成 |
まとめ
さて、今回はソースコードが長くはなりましたが、スクレイピングでほしいデータを狙いうちするための条件分岐が多くなったことが主な原因でした。(もう少しうまく書ければ…)
対象とするページのhtmlを確認しながら条件分岐を増やしていくことで自分が欲しいデータを取得していくことが大事です。
楽々スクレイピングと言いながら、意外と苦しみましたが、ソースコード自体は単純になっています。
ユーザビリティを考え、コンボボックスなどを使うのも良いですね。(まあ、半年に1回しか使わないのですが…)
欲しいデータを一度に大量に取得できるようになるとお仕事がはかどること間違いなしですよ。

