こんにちは!最近PythonでちょこちょこプログラミングをしているS.K.です。
ついに、ついにここまでやってきました…私がPythonをやるなら作ってみたいと思った目標の一つ!!
そう、今回はOCRをやってみました!!
ちなみにOCRとは、手書きや印刷された文字を、スキャナなどで読み取って、PCで利用できるように変換する技術のことです。名刺の写真を撮ったら文字を読み取ってくれるみたいなアプリも有名ですよね。
今回は画像(png)とPDFを読み取ってメモ帳などに貼り付けれるようにしました。(この記事では画像の読み取りを主に紹介していきます)
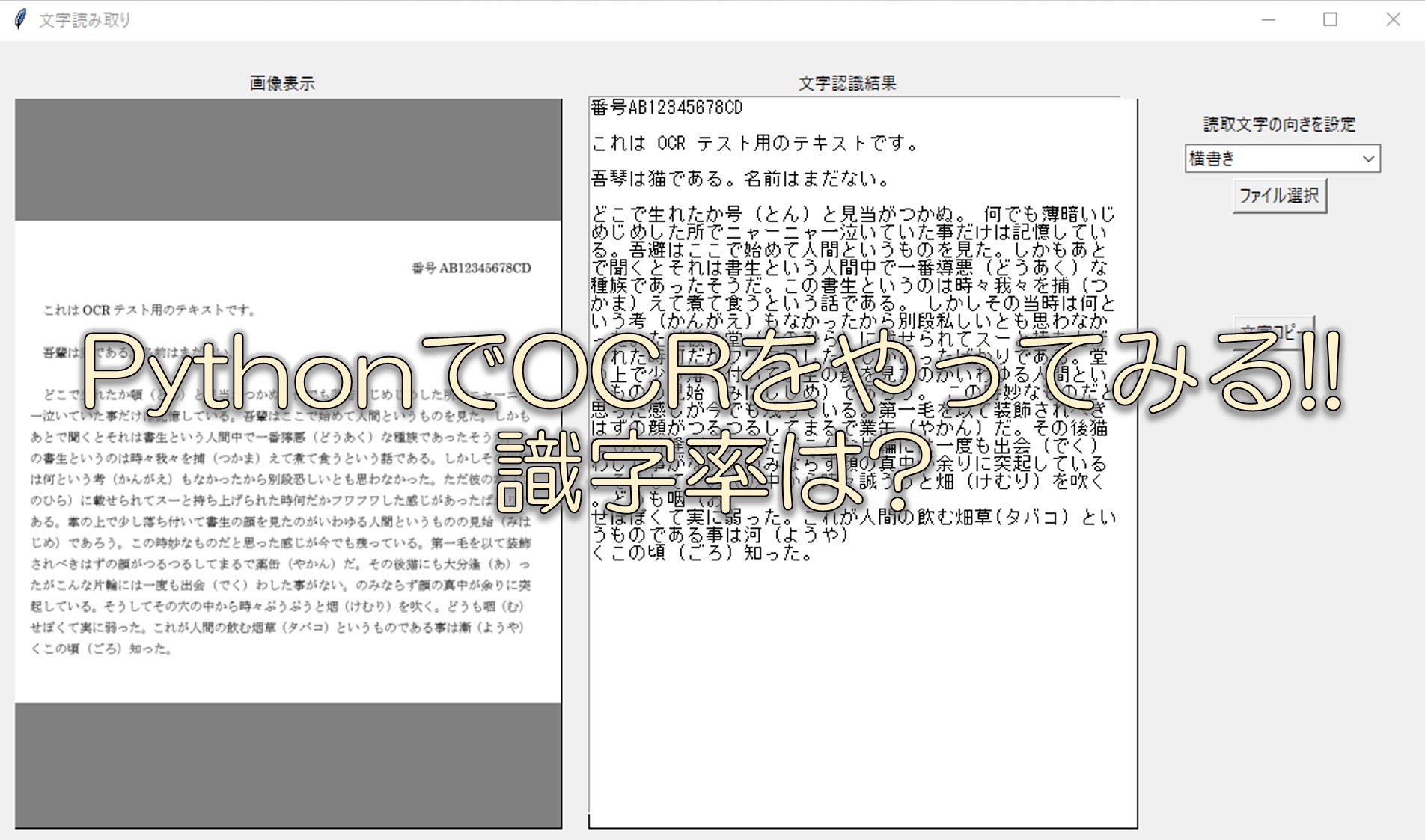
画面は毎度おなじみのGUIです。一度やり出すとボタンの位置はここ!!みたいなこだわりが出てきてしまいますが、ユーザビリティは大事!!
とはいえ、一番の問題は識字率(どれだけ文字を正確に読み取れるか)です。
それでは、紹介していきます。
PythonでOCRを行うには?
何はともあれ、どんなのなの?と思われるせっかちなあなたに、今回作ったプログラムを動かしている動画です。
動画では画像(png)の文字読み取りを行っています。
OCRを実施するために、Googleが開発元の「tesseract-OCR」を使っています。tesseract-OCRはオープンソースなので誰でも使えます。
そして、tesseract-OCRをPythonで使えるようにするためのライブラリが「pyocr」です。
これを使うことでtesseract-OCRをPythonで使えるようになります。
画像から文字起こしをする手順
tesseract-OCRとpyocrで画像から文字起こしするざっくりとした手順です。
①tesseract-OCRをインストールする
まずはtesseract-OCRをインストールします。
インストールが完了すると「tesseract-OCR」フォルダができます。これを、C:¥Program Filesの中に移動します。
②日本語の教師データをダウンロードする
読み取る文字を変換するために大本となるデータ(教師データ)が必要になります。最初から英語の教師データは入っているのですが、日本語の教師データは入っていないので追加します。

こちらのUpdated Data Files for Version 4.00のtessdataからデータを取得します。
横書き用の「jpn.traineddata」と縦書き用「jpn_vert.traineddata」の2つをダウンロードして、tesseract-OCRフォルダ内のtessdataフォルダに移しておきます。(tessdataフォルダが教師用データを保存しているフォルダになります)
③tesseract-OCRフォルダにPathを通す
コントロールパネルーシステムーシステムの詳細設定ー環境変数とクリックしていき、システム環境変数のPathをダブルクリック、開いたウインドウの右上の「新規」をクリックし、C:¥Program Files¥Tesseract-OCRと記入して、OKをクリックします。
次に、「TESSDATA_PREFIX」という環境変数を新たに作ります。
システム環境変数の「新規」をクリックし、
変数名 TESSDATA_PREFIX
変数値 C:¥Program Files¥Tesseract-OCR¥tessdata
と入力てOKをクリックします。終わったら、パソコンを再起動してください。
④pyocrをインストールする
コマンドプロンプトを立ち上げて、pyocrをインストールします。
⑤Pythonでプログラムを作成する
メインのtesseract-OCRを呼び出して、画像から日本語文字を読み取るにはこのようなソースコードになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# Tesseract-OCRを呼び出す tools = pyocr.get_available_tools() tool = tools[0] # 画像から日本語文字を読み取る texts = [] txt = tool.image_to_string( path, # 画像のファイルパス lang="jpn", # 日本語を設定(横書き:jpn、縦書き:jpn_vert) builder=pyocr.builders.TextBuilder(tesseract_layout=6) # 結果をテキストとして受け取る(横書き:6、縦書き:5) ) result = re.sub('([あ-んア-ン一-龥ー])\s+((?=[あ-んア-ン一-龥ー]))',r'\1\2', txt) texts.append(result) |
textsに読み取った文字が入っているはずです。
どのように表示させるかなどは考えてみてくださいね♪
まとめ
まあ、動画見ていただくとわかってしまうのですが、文字を読み取ることはできました。
ただ、識字率は正直もう少し読み取れて欲しかったというのが本音です。
(いろいろと調整を行うことで読み取り精度を向上できるらしいのですが、なかなかに難しく…)
とはいえ、ここまで作りこめたのも事実!!私がんばった(笑)
機会があれば読み取り精度向上もやってみたいと思います。
私はOCRを導入するところでかなりつまずいたので、そこさえ超えれば、自分がどのような形で読み取れるようにしたいかを考えて作っていくことができると思います。
お試しあれ!!